java知识随笔
java做题知识随笔
接口与抽象类
抽象类不能实例化。抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。由于不能实例化对象,所以抽象类必须被继承,才能被使用。父类包含了子类集合的常见的方法,但是由于父类本身是抽象的,所以不能使用这些方法。
接口更多的是在系统架构设计方法发挥作用,主要用于定义模块之间的通信契约。而抽象类在代码实现方面发挥作用,可以实现代码的重用。
接口与抽象类的区别:
- 抽象类可以有构造方法,接口中不能有构造方法。
- 抽象类中可以有普通成员变量,接口中没有普通成员变量
- 抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
- 抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然 eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
- 抽象类中可以包含静态方法,接口中不能包含静态方法
- 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型。
- 一个类可以实现多个接口,但只能继承一个抽象类。
- 抽象方法不能含有方法体,且必须在抽象类中
示例
例如,模板方法设计模式是抽象类的一个典型应用,假设某个项目的所有Servlet类都要用相同的方式进行权限判断、记录访问日志和处理异常,那么就可以定义一个抽象的基类,让所有的Servlet都继承这个抽象基类,在抽象基类的service方法中完成权限判断、记录访问日志和处理异常的代码,在各个子类中只是完成各自的业务逻辑代码,伪代码如下:
1 | package com; |
实现类如下:
1 | package com; |
父类方法中间的某段代码不确定,留给子类干,就用模板方法设计模式。
异常捕获
当程序执行到try{}语句中的return方法时,它会干这么一件事,将要返回的结果存储到一个临时栈中,然后程序不会立即返回,而是去执行finally{}中的程序。执行完之后,就会通知主程序“finally的程序执行完毕,可以请求返回了”,这时,就会将临时栈中的值取出来返回。
try-catch、try-finally、try-catch-finally,但catch和finally语句不能同时省略!
try-catch-finally块中,finally块在以下几种情况将不会执行。
(1)finally块中发生了异常。
(2)程序所在线程死亡。
(3)在前面的代码中用了System.exit();
(4)关闭了Cpu
表达式
&& 和 || 为短路与和短路或。&& 若前面的表达式为false,整个逻辑表达式为false,所以后面的表达式无论true和false都无法影响整个表达式的逻辑结果,所以为了提高代码执行速率,这里后面的表达式就不会执行。同理, || 若前面表达式为true,则后面的表达式无需计算。**& 和 | 为不短路与不短路或**。无论什么情况,前面的和后面的都要执行。
Mybatis中的#和$
PreparedStatement有预编译的过程,已经绑定sql,之后无论执行多少遍,都不会再去进行编译,执行速度要比statement 快,安全性高,可以防止SQL注入。而 statement 不同,如果执行多遍,则相应的就要编译多少遍sql。
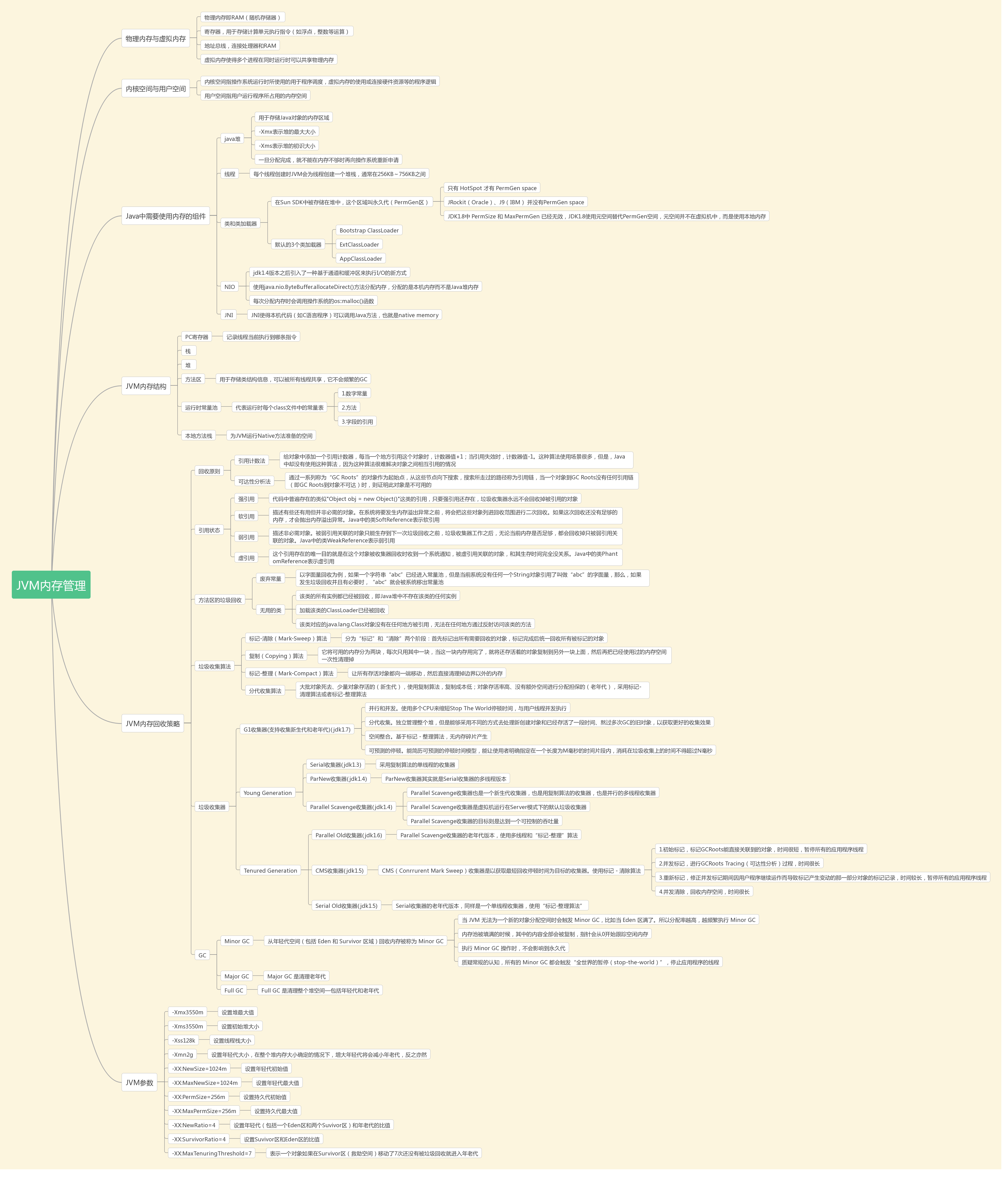
JVM的垃圾回收机制
关于JVM的垃圾回收机制:
- 垃圾回收在jvm中优先级相当相当低。
- 垃圾收集器(GC)程序开发者只能推荐JVM进行回收,但何时回收,回收哪些,程序员不能控制。
- 垃圾回收机制只是回收不再使用的JVM内存,如果程序有严重BUG,照样内存溢出。
- 进入DEAD的线程,它还可以恢复,GC不会回收。
静态域
静态域:分为静态变量,静态方法,静态块。这里面涉及到的是静态变量和静态块,当执行到静态域时,按照静态域的顺序加载,并且静态域只在类的第一次加载时执行。
static修饰的成员属于类成员,父类变量或方法只能被子类同名变量或方法遮蔽,不能被继承覆盖
静态成员变量或静态代码块>main方法>非静态成员变量或非静态代码块>构造方法
父类静态成员变量 父类静态代码块 子类静态成员变量 子类静态代码块 父类非静态成员变量,父类非静态代码块,父类构造函数,子类非静态成员变量,子类非静态代码块,子类构造函数
子类的构造方法总是先调用父类的构造方法,如果子类的构造方法没有明显地指明使用父类的哪个构造方法,子类就调用父类不带参数的构造方法。
而父类没有无参的构造函数,所以子类需要在自己的构造函数中显示的调用父类的构造函数。
重载与重写
方法重载,参数列表不相同,返回值类型可以不同;方法重写,遵循两同-两小-一大规则。两同:方法名和参数列表相同;两小:子类返回值类型小于等于父类的,异常抛出小于等于父类;一大:访问权限修饰符大于等于父类。
字面量”+”拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的”+”拼接运算是在运行时进行的,新创建的字符串存放在堆中。
构造方法
构造方法是一种特殊的方法,具有以下特点:
(1)构造方法的方法名必须与类名相同。
(2)构造方法没有返回类型,也不能定义为void,在方法名前面不声明方法类型。
(3)构造方法的主要作用是完成对象的初始化工作,它能够把定义对象时的参数传给对象的域。
(4)一个类可以定义多个构造方法,如果在定义类时没有定义构造方法,则编译系统会自动插入一个无参数的默认构造器,这个构造器不执行任何代码。
(5)构造方法可以重载,,而且可以使用super()、this()相互调用,以参数的个数,类型,顺序区分。
(6)每个构造器的默认第一行都是super(),但是一旦父类中没有无参构造,必须在子类的第一行显式的声明调用哪一个构造。
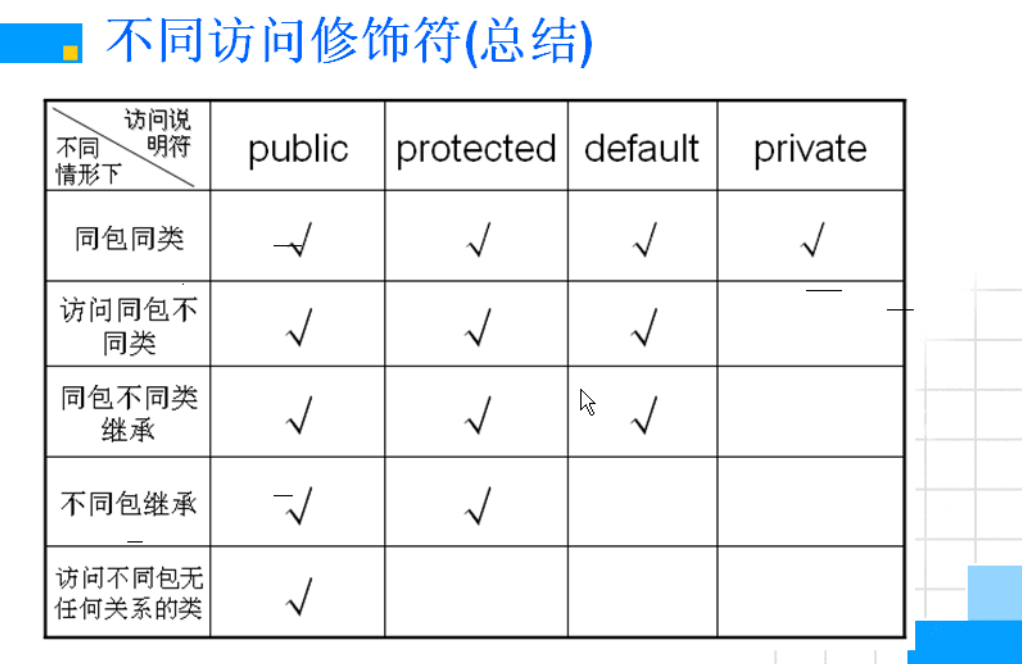
修饰符
| 修饰符 | 类 | 成员方法 | 构造方法 | 成员变量 | 局部变量 |
|---|---|---|---|---|---|
| abstract(抽象的) | √ | √ | - | - | - |
| static (静态的) | - | √ | - | √ | - |
| public(公共的) | √ | √ | √ | √ | - |
| protected(受保护的) | √ | √ | √ | - | |
| private(私有的) | - | √ | √ | √ | - |
| synchronized(同步的) | - | √ | - | - | - |
| native(本地的) | - | √ | - | - | - |
| transient(暂时的) | - | - | - | √ | - |
| volatie(易失的) | - | - | - | √ | - |
| final(不要改变的) | √ | √ | - | √ | √ |
线程安全的集合对象
vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
Stack:堆栈类,先进后出
hashtable:就比hashmap多了个线程安全
enumeration:枚举,相当于迭代器
非线程安全的集合对象
- ArrayList
- LinkedList
- HashMap
- HashSet
- TreeMap
- TreeSet
- StringBulider
创建对象方式
使用 new 关键字(最常用):
ObjectName obj = new ObjectName();使用反射的Class类的newInstance()方法:
ObjectName obj = ObjectName.class.newInstance();使用反射的Constructor类的newInstance()方法:
ObjectName obj = ObjectName.class.getConstructor.newInstance();使用对象克隆clone()方法:
ObjectName obj = obj.clone();使用反序列化(ObjectInputStream)的readObject()方法:
1 | try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(FILE_NAME))) { |
map分类
java为数据结构中的映射定义了一个接口java.util.Map。它有四个实现类,分别是HashMap、HashTable、LinkedHashMap 和TreeMap。
HashMap是无序存放的,key或value可以保存为null,非线程安全
Hashtable是无序存放的,key不允许设置为null,线程安全
ConcurrentHashMap是无序存放的,key或value可以保存为null,线程安全
TreeMap是可以排序的Map集合,按集合中的key排序,key不允许有重复,非线程安全
LinkedHashMap是HashMap的子类,保存了记录的插入顺序,遍历的时候比HashMap效率低,非线程安全
Hashmap 根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,取得数据的顺序是完全随机的。 HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,。
Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
LinkedHashMap 是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,当HashMap容量很大,实际数据较少时,遍历起来可能会比 LinkedHashMap慢。因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
面向对象的六原则一法则
单一职责原则
一个类只做它该做的事情。(单一职责原则想表达的就是”高内聚”,写代码最终极的原则只有六个字”高内聚、低耦合”,所谓的高内聚就是一个代码模块只完成一项功能,在面向对象中,如果只让一个类完成它该做的事,而不涉及与它无关的领域就是践行了高内聚的原则,这个类就只有单一职责。另一个是模块化,好的自行车是组装车,从减震叉、刹车到变速器,所有的部件都是可以拆卸和重新组装的,好的乒乓球拍也不是成品拍,一定是底板和胶皮可以拆分和自行组装的,一个好的软件系统,它里面的每个功能模块也应该是可以轻易的拿到其他系统中使用的,这样才能实现软件复用的目标。)
开闭原则
软件实体应当对扩展开放,对修改关闭。(在理想的状态下,当我们需要为一个软件系统增加新功能时,只需要从原来的系统派生出一些新类就可以,不需要修改原来的任何一行代码。要做到开闭有两个要点:①抽象是关键,一个系统中如果没有抽象类或接口系统就没有扩展点;②封装可变性,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而换乱,如果不清楚如何封装可变性,可以参考《设计模式精解》一书中对桥梁模式的讲解的章节。)
依赖倒转原则
面向接口编程。(该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代,请参考下面的里氏替换原则。)
里氏替换原则
任何时候都可以用子类型替换掉父类型。(关于里氏替换原则的描述,Barbara Liskov女士的描述比这个要复杂得多,但简单的说就是能用父类型的地方就一定能使用子类型。里氏替换原则可以检查继承关系是否合理,如果一个继承关系违背了里氏替换原则,那么这个继承关系一定是错误的,需要对代码进行重构。例如让猫继承狗,或者狗继承猫,又或者让正方形继承长方形都是错误的继承关系,因为你很容易找到违反里氏替换原则的场景。需要注意的是:子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。)
接口隔离原则
接口要小而专,绝不能大而全。(臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。例如,琴棋书画就应该分别设计为四个接口,而不应设计成一个接口中的四个方法,因为如果设计成一个接口中的四个方法,那么这个接口很难用,毕竟琴棋书画四样都精通的人还是少数,而如果设计成四个接口,会几项就实现几个接口,这样的话每个接口被复用的可能性是很高的。Java中的接口代表能力、代表约定、代表角色,能否正确的使用接口一定是编程水平高低的重要标识。)
合成聚合复用原则
优先使用聚合或合成关系复用代码。(通过继承来复用代码是面向对象程序设计中被滥用得最多的东西,因为所有的教科书都无一例外的对继承进行了鼓吹从而误导了初学者,类与类之间简单的说有三种关系,Is-A关系、Has-A关系、Use-A关系,分别代表继承、关联和依赖。其中,关联关系根据其关联的强度又可以进一步划分为关联、聚合和合成,但说白了都是Has-A关系,合成聚合复用原则想表达的是优先考虑Has-A关系而不是Is-A关系复用代码,原因嘛可以自己从百度上找到一万个理由,需要说明的是,即使在Java的API中也有不少滥用继承的例子,例如Properties类继承了Hashtable类,Stack类继承了Vector类,这些继承明显就是错误的,更好的做法是在Properties类中放置一个Hashtable类型的成员并且将其键和值都设置为字符串来存储数据,而Stack类的设计也应该是在Stack类中放一个Vector对象来存储数据。记住:任何时候都不要继承工具类,工具是可以拥有并可以使用的,而不是拿来继承的。)
迪米特法则
迪米特法则又叫最少知识原则,一个对象应当对其他对象有尽可能少的了解。再复杂的系统都可以为用户提供一个简单的门面,Java Web开发中作为前端控制器的Servlet或Filter不就是一个门面吗,浏览器对服务器的运作方式一无所知,但是通过前端控制器就能够根据你的请求得到相应的服务。调停者模式也可以举一个简单的例子来说明,例如一台计算机,CPU、内存、硬盘、显卡、声卡各种设备需要相互配合才能很好的工作,但是如果这些东西都直接连接到一起,计算机的布线将异常复杂,在这种情况下,主板作为一个调停者的身份出现,它将各个设备连接在一起而不需要每个设备之间直接交换数据,这样就减小了系统的耦合度和复杂度。
类的加载过程
如下图所示,JVM类加载机制分为五个部分:加载,验证,准备,解析,初始化,下面我们就分别来看一下这五个过程。
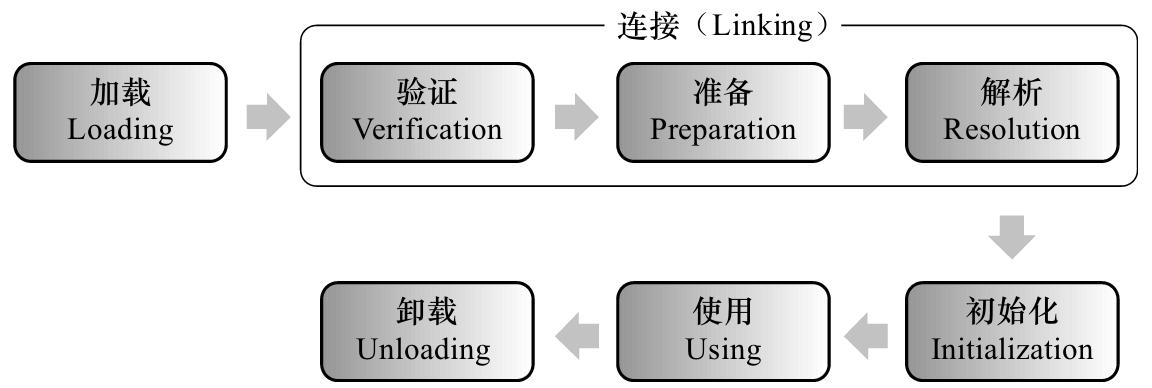
加载
加载是类加载过程中的一个阶段,这个阶段会在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的入口。注意这里不一定非得要从一个Class文件获取,这里既可以从ZIP包中读取(比如从jar包和war包中读取),也可以在运行时计算生成(动态代理),也可以由其它文件生成(比如将JSP文件转换成对应的Class类)。
验证
这一阶段的主要目的是为了确保Class文件的字节流中包含的信息是否符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
准备
准备阶段是正式为类变量分配内存并设置类变量的初始值阶段,即在方法区中分配这些变量所使用的内存空间。注意这里所说的初始值概念,比如一个类变量定义为: public static int v = 8080;实际上变量v在准备阶段过后的初始值为0而不是8080,将v赋值为8080的putstatic指令是程序被编译后,存放于类构造器方法之中。但是注意如果声明为:public static final int v = 8080;在编译阶段会为v生成ConstantValue属性,在准备阶段虚拟机会根据ConstantValue属性将v赋值为8080。
解析
解析阶段是指虚拟机将常量池中的符号引用替换为直接引用的过程。符号引用就是class文件中的:CONSTANT_Class_info、CONSTANT_Field_info、CONSTANT_Method_info等类型的常量。
初始化
初始化阶段是类加载最后一个阶段,前面的类加载阶段之后,除了在加载阶段可以自定义类加载器以外,其它操作都由JVM主导。到了初始阶段,才开始真正执行类中定义的Java程序代码。
初始化阶段是执行类构造器方法的过程。方法是由编译器自动收集类中的类变量的赋值操作和静态语句块中的语句合并而成的。虚拟机会保证方法执行之前,父类的方法已经执行完毕。p.s: 如果一个类中没有对静态变量赋值也没有静态语句块,那么编译器可以不为这个类生成()方法。
注意以下几种情况不会执行类初始化:
通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
定义对象数组,不会触发该类的初始化。
常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类。
通过类名获取Class对象,不会触发类的初始化。
通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。
通过ClassLoader默认的loadClass方法,也不会触发初始化动作。
Cookie和Session的区别
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
类加载机制、双亲委派模型
某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
双亲委派模型的好处:
主要是为了安全性,避免用户自己编写的类动态替换 Java的一些核心类,比如 String。
同时也避免了类的重复加载,因为 JVM中区分不同类,不仅仅是根据类名,相同的 class文件被不同的 ClassLoader加载就是不同的两个类